AI Product · Multimodal Judgment · RAG · System Design
Encoding Design Judgment — A Visual Standard Assistant
电商主图视觉标准对齐助手 · 把资深设计师的隐性判断显性化
2026
01 | 问题背景 Background
一家多品牌、多渠道的大健康电商公司,视觉设计团队为旗下多个品牌产出电商主图。我把范围聚焦在「商品主图」——它最标准化、杠杆也最高:主图直接决定搜索与列表页的点击和转化。
A multi-brand, multi-channel health & wellness e-commerce company, whose design team produces marketplace main-images across many brands. I scoped the project to product main-images — the most standardized, highest-leverage surface: the main-image directly drives click-through and conversion on search and listing pages.
团队真正的瓶颈不在「出图快不快」——产能和速度公司已有工具覆盖。瓶颈在新人判断不准方向:公司多品牌、多渠道,没有统一的「长相」,真正在起作用的,是一套功效驱动型主图语法。它内化在资深设计师脑中、从未被写下来——教不了新人,也无法检查。于是新人要么误判跑偏、反复返工,要么事事问资深、上手慢。
The real bottleneck wasn't production speed — throughput was already tool-covered. It was that junior designers couldn't judge direction. Across many brands there is no single "look"; what actually governs quality is a tacit efficacy-driven main-image grammar that lives in senior designers' heads, never written down — so it can't be taught and can't be checked. Juniors either misjudge and rework repeatedly, or ask seniors for everything and ramp slowly.
瓶颈不在「画得快不快」,而在「判断得准不准」。
The bottleneck isn't how fast you draw — it's how accurately you judge.
所以我把问题钉在生成之前的那一环——「标准对齐与判断」,刻意不碰已有工具覆盖的出图产能。这既不与现有工具重叠,也正对准老板真正要的目标:加速新人上手。
So I anchored the problem at the step before generation — standard alignment and judgment — deliberately not touching the image-generation throughput that existing tools already cover. This neither overlaps with current tooling nor misses the actual goal: ramping juniors faster.
02 | 方案:两层标准 + 对齐助手 The Solution: A Two-Layer Standard + an Alignment Assistant
核心思路:把资深设计师脑中那套隐性语法显性化、可检查化,做成一个新人上传稿子即得判断的对齐助手。它不生成图片(不碰出图工具)、不替代设计师——只把「判断力」做成随时可用的工具。
The core idea: make that tacit grammar explicit and checkable, as an assistant where a junior uploads a draft and gets a judgment back. It does not generate images (it stays away from the production tools) and does not replace designers — it turns judgment itself into an always-available tool.
两层标准是方案的战略核心:
The two-layer standard is the strategic core:
-
第一层 · 不变的功效语法:功效大标题、问题/利益点、产品主角、信任背书、背景克制、底部转化模块。
-
第二层 · 随品类的视觉皮肤:颜色、人物、气质、场景。
-
Layer 1 · the invariant efficacy grammar: a benefit headline, problem/benefit points, the product as hero, trust endorsements, a restrained background, a bottom conversion module.
-
Layer 2 · a per-category visual skin: color, models, mood, scene.
这意味着标准锁的是「转化语法」、放开的是「视觉皮肤」。所以它能正确处理多品牌的现实——婴童护理的粉白、不同品类的不同气质,都不会被误判成跑偏;真正的跑偏,是语法塌掉(变成种草氛围、功效不前置、产品被弱化)。
So the standard locks the conversion grammar and frees the visual skin. That lets it handle a multi-brand reality correctly: baby-care pink-white, different moods per category — none flagged as off-standard. The real failure is when the grammar collapses (it turns into lifestyle mood, efficacy isn't foregrounded, the product gets weakened).
我还引入了一条「视觉说服范式」判别轴(功效驱动 / 品牌驱动 / 混合),让系统判的是「这张图靠什么说服用户」,而不只是数「有没有标题、有没有产品」——避免把高端品牌感误当成功效型主图的加分项。
I also added a visual-persuasion paradigm axis (efficacy-driven / brand-driven / hybrid), so the system judges what an image persuades with, not just whether it has a headline and a product — preventing it from mistaking high-end brand polish for an efficacy-image merit.
03 | 能跑的 MVP A Working MVP
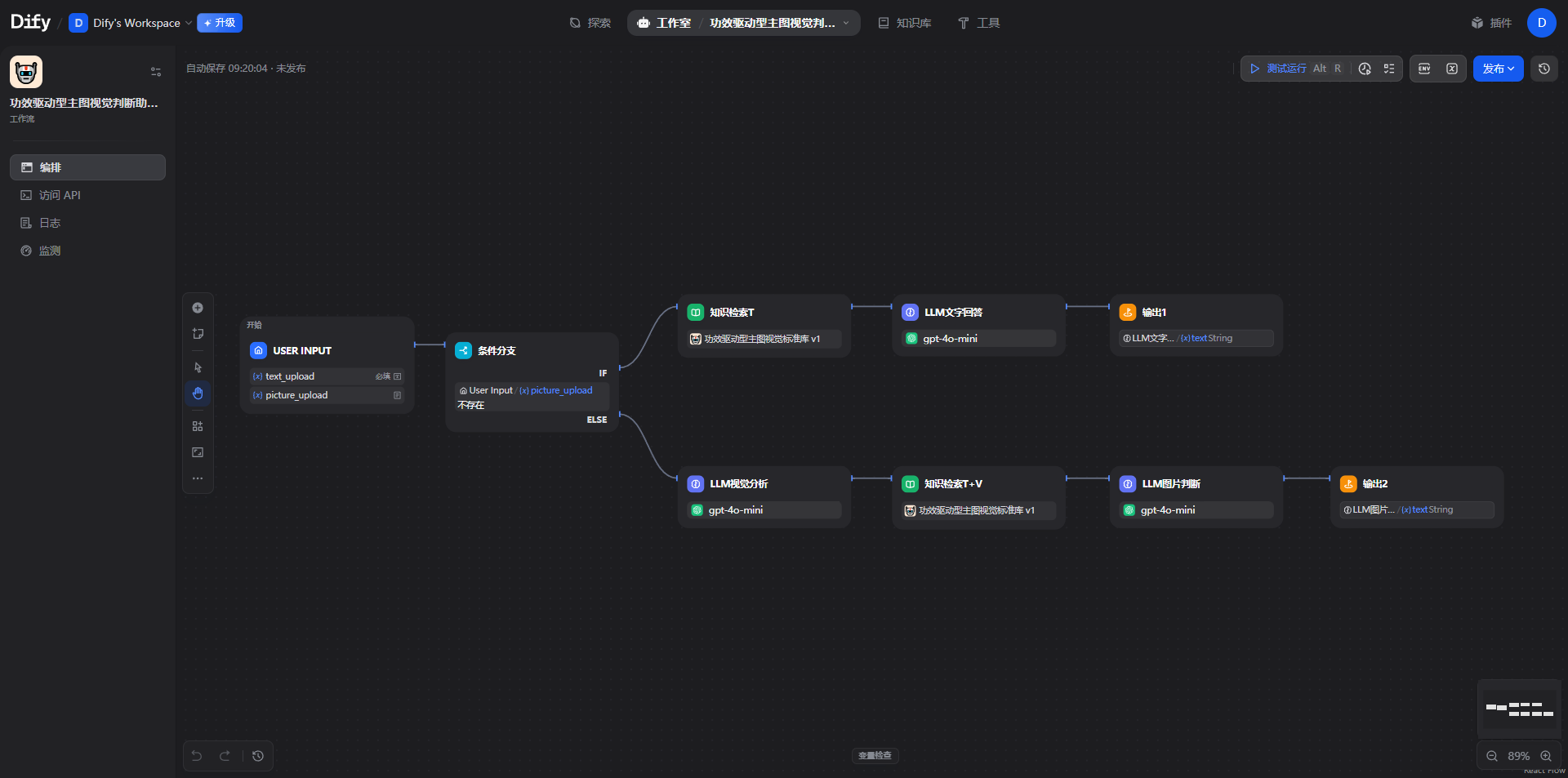
我在 Dify 上搭了一个双模式 agent,以「有没有上传图片」分流,覆盖新人两类真实场景:
I built a dual-mode agent on Dify, branching on whether an image was uploaded, to cover a junior's two real situations:
-
判图(主功能):有图 → 视觉分析 → 知识检索 → 图片判断 → 输出「总体判断 / 符合点 / 跑偏点 / 修改建议 / 可参考案例」
-
问答(辅助):无图 → 知识检索 → 文字回答,日常查标准、问设计边界
-
Judge-image (primary): image in → visual analysis → knowledge retrieval → image judgment → output: overall verdict / on-standard / off-standard / fixes / reference cases.
-
Q&A (secondary): no image → knowledge retrieval → text answer, for everyday questions about the standard and design boundaries.
几个设计取舍:
A few design tradeoffs:
-
先观察、后判断分离:先让模型客观描述图里有什么,再对照标准下判断,避免「边看边下结论」的草率。
-
判断前必过知识库:判定锚在显性标准 + 案例库(RAG)上,不靠模型凭空感觉,结果可追溯、可解释。
-
全链路用最小模型(gpt-4o-mini):运行成本近乎为零——而且下一节会看到,能力瓶颈根本不在模型。
-
Separate observe-then-judge: first have the model objectively describe the image, then judge against the standard — avoiding snap conclusions.
-
Judgment must pass the knowledge base: verdicts are anchored to the explicit standard + a case library (RAG), not the model's free-floating intuition — so results are traceable and explainable.
-
Smallest model end-to-end (gpt-4o-mini): running cost is near zero — and as the next section shows, the capability bottleneck isn't the model at all.
04 | 关键迭代:v1.0 → v1.1 Key Iteration
从 v1.0 到 v1.1,系统暴露出两个判断错误。两处都靠系统设计修正,而不是换更贵的模型。
From v1.0 to v1.1, the system surfaced two judgment errors. Both were fixed through system design, not a pricier model.
问题一:把「粉色」误判为跑偏。 v1.0 把一张婴童护理品类的主图(粉白调)判成偏离标准。诊断:系统把「某个对标样本的配色」当成了标准本身。修复:引入两层模型——语法不变、皮肤随品类。验证:同一张图被判为「高度接近」,粉色不再被冤判。
Error 1: pink misjudged as off-standard. v1.0 flagged a baby-care main-image (pink-white) as deviating. Diagnosis: the system had mistaken one reference sample's palette for the standard itself. Fix: the two-layer model — grammar fixed, skin per category. Result: the same image was re-judged "highly aligned"; pink was no longer wrongly penalized.
问题二:品牌驱动型主图判得太松。 v1.0 把一张高端护肤品牌的品牌驱动型主图判成「基本接近」,甚至把「高端感」当加分项。诊断:系统在数表面要素(有没有标题 / 产品 / 背书),没判「靠什么说服用户」。修复:把视觉分析结构化,新增「视觉说服范式」判别轴。验证:同一张图从「基本接近」降为「部分接近」,范式被正确区分。
Error 2: a brand-driven image judged too leniently. v1.0 rated a high-end skincare brand's brand-driven main-image as "broadly aligned," even crediting its "premium feel." Diagnosis: the system was counting surface elements (headline / product / endorsement) instead of judging what it persuades with. Fix: structure the visual analysis and add the persuasion-paradigm axis. Result: the same image dropped from "broadly aligned" to "partially aligned"; the paradigm was correctly distinguished.
以下案例图为原创 mock 图,品牌与商品均为虚构,仅用于展示系统的判断逻辑。
Mock images below are original; brands and products are fictional, shown only to illustrate the system's judgment logic.

案例 A · 品类适配正例:婴童护理主图
核心原因
该图整体符合功效驱动型主图语法。虽然使用了粉色与婴童元素,但它们与婴童护理品类高度适配,并没有削弱功效表达。画面仍然保持了功效前置、产品突出、信任背书和底部转化信息的完整结构。
符合点
- 1.功效大标题明确,能够快速传达产品定位与核心作用。
- 2.问题 / 利益点以勾选形式呈现,直接对应用户可能遇到的护理场景。
- 3.产品主体清晰,包装与产品组合占据主要视觉区域,识别度高。
- 4.信任背书明确,如温和配方、敏感肌适用、渠道背书等信息增强可信度。
- 5.底部转化 / 利益补充模块完整,能够进一步强化购买理由。
跑偏点 / 可优化点
基本没有明显跑偏,以下为可优化点:
- 1.可进一步增强标题与勾选列表之间的层级区分,让用户浏览时更快抓住重点。
- 2.底部模块可适当减少信息密度,避免在小尺寸展示时可读性下降。
可参考方向
品类适配正例;婴童护理类功效型主图;「语法稳定,皮肤随品类变化」的标准样本。

案例 B · 功效型正例:抗老精华主图
核心原因
该图符合功效驱动型主图的核心结构:功效标题清晰、产品主体突出、问题 / 利益点明确、信任背书可见,并且具备底部利益总结。整体说服逻辑以「问题—功效—产品—背书—转化」为主,而不是单纯依赖品牌氛围。
符合点
- 1.主标题直接表达「紧致抗皱」等核心功效,信息进入速度快。
- 2.勾选式利益点清晰列出用户关心的问题,如细纹、松弛、轮廓、肤感等。
- 3.产品主体占据主要视觉区域,包装清晰,主次关系明确。
- 4.信任背书围绕功效建立,例如成分复配、实验验证等,能够增强可信度。
- 5.底部利益条对核心卖点进行总结,强化转化导向。
跑偏点 / 可优化点
基本没有明显跑偏,以下为可优化点:
- 1.可进一步增强信任背书与产品之间的关联,让用户更快理解「为什么可信」。
- 2.背景质感偏高级,可注意避免过度品牌化,保持功效信息优先。
可参考方向
功效型护肤主图正例;抗老精华类主图;医研感 / 成分功效型视觉表达。

案例 C · 品牌驱动反例:高端护肤海报型主图
核心原因
该图产品清晰、画面高级、背景克制,但整体更偏品牌驱动型视觉。它主要依靠品牌氛围、产品质感和高端审美说服用户,缺少明确的问题 / 利益点勾选、功效型信任背书和强转化模块,因此不完全符合功效驱动型主图标准。
符合点
- 1.产品主体清晰,包装识别度较高。
- 2.背景克制,没有明显干扰产品展示。
- 3.标题可读,能够传达一定的产品方向。
跑偏点 / 可优化点
- 1.缺少明确的问题 / 利益点勾选,用户无法快速理解产品解决什么具体问题。
- 2.信任背书偏品牌氛围,缺少认证、成分、实验验证、渠道背书等功效型信任信息。
- 3.底部模块较弱,未形成明确的购买引导或利益补充。
- 4.整体更像品牌海报 / 形象图,而不是以功效转化为核心的信息型主图。
可参考方向
品牌驱动型反例;高端护肤海报型主图;范式不匹配样本。
迭代验证 · 从「要素识别」升级为「范式判断」
测试现象
初版系统在判断高端护肤图时,容易把「产品清晰、标题存在、品牌感强」误认为符合功效驱动型标准,因此对品牌驱动型主图判得偏松。
A/B 测试结果
在相同任务下,将基础模型替换为更强模型后,判断结论并没有明显改善。说明问题的主要瓶颈不在模型能力,而在任务定义:系统只是在数「有没有标题、有没有产品、有没有背书」,没有判断这张图到底靠什么说服用户。
修正方式
v1.1 中新增「视觉说服范式」判别轴,将图像先区分为:功效驱动型 / 品牌驱动型 / 混合型 / 其他。同时加入两层判断模型:① 稳定语法——功效标题、问题 / 利益点、产品主角、信任背书、底部转化模块;② 品类皮肤——颜色、人物、气质、场景随品类变化。
迭代结果
系统不再单纯判断「要素齐不齐」,而是进一步判断「这张图的核心说服逻辑是什么」。因此,粉色婴童护理图可以被判为高度接近,而高端品牌海报型护肤图会被识别为部分接近。
项目价值
这次迭代证明:AI 判断类工具的关键不只是换更强模型,而是把任务定义设计得更准确。通过结构化观察、知识库检索和范式判断,系统才能更接近真实设计主管的判断逻辑。
同一任务换更大的模型,结果几乎不变——瓶颈不在模型能力,在任务定义。
Swap in a bigger model on the same task and the result barely moves — the bottleneck isn't model capability, it's task definition.
05 | 诚实的价值与局限 Honest Value & Limits
我刻意只把最硬、最可辩护的一块做量化:新人因「判断不准」产生的返工工时。按一组保守的、可替换的示意假设算下来,直接可省的工时约 ¥0.7–2 万 / 年,随团队扩招线性放大。这个数字不大——它是 ROI 的保底线,不是卖点。
I deliberately quantified only the hardest, most defensible piece: rework hours from juniors' misjudgment. On conservative, replaceable illustrative assumptions, the directly-saveable hours come to roughly ¥7k–20k/year, scaling with hiring. It's a small number — the floor of the ROI, not the pitch.
真正值钱的在战略层,我如实标为方向性上行、需真实数据验证,不编成数字塞进总账:
The real value is strategic, which I marked honestly as directional upside pending real data rather than forcing into the total:
-
新人上手提速(老板真正的目标)——一个 6 周就靠谱的新人,远胜 12 周才靠谱的。
-
更多主图落在被验证过的转化语法上——主图是点击命门,转化的微小改善对应的 GMV 增量,量级上通常压过全部工时节省。此项须用真实转化数据验证,不作承诺。
-
可复制资产——同一套「标准 + 判断助手」可平移到其他品类与物料,边际成本低。
-
Faster ramp for juniors (the actual goal) — a junior reliable in 6 weeks beats one who takes 12.
-
More main-images on a validated conversion grammar — the main-image is the click pressure-point; a small conversion lift usually dwarfs all hour-savings in GMV terms. This must be verified with real conversion data; no promises made.
-
A replicable asset — the same "standard + judgment assistant" method ports to other categories and materials at low marginal cost.
诚实的局限:① 小模型偶尔仍会把「品牌型背书」误算为加分项(表面匹配的残留),下一版用更细的背书分类解决;② 目前只覆盖「商品主图」一类,其他物料需另立标准;③ 价值验证仍基于假设,需用真实业务数据(出图量、返工轮次、转化率)校准。
Honest limits: (1) the small model still occasionally counts brand-type endorsement as a merit (residual surface-matching); a finer endorsement taxonomy fixes it next version. (2) It covers only product main-images for now; other materials need their own standard. (3) The value case still rests on assumptions and needs calibration against real business data (image volume, rework rounds, conversion).