RAG · Vector Search · Prompt Engineering · Domain Knowledge
Cross-Platform RAG — Fire Code QA Assistant
建筑防火规范智能问答助手 · 跨平台 RAG 对照实践
2026
在线体验 / Live — Coze 版 ↗ · Dify 版 ↗
01 | 问题背景 Background
建筑设计师在日常工作中需要频繁查询防火规范条款。传统 PDF 检索存在三个痛点:无法用自然语言提问、跨条款关联回答困难、条款修订后的版本追踪繁琐。GB 55037-2022 作为 2023 年新颁布的强制性通用规范,其条款已成为日常设计审查的高频参考。
Architects need to look up fire-code clauses constantly, and traditional PDF search has three pain points: you can't ask in natural language, cross-clause reasoning is hard, and tracking versions after a clause is revised is tedious. GB 55037-2022 — a mandatory general code issued in 2023 — has become a high-frequency reference in everyday design review.
本项目以 GB 55037-2022 为知识源,搭建一个具备条款级引用追溯能力的 RAG 智能问答助手,在 Coze 与 Dify 两个主流低代码平台分别独立实现,并通过对比实验量化两套架构的工程权衡。
This project uses GB 55037-2022 as the knowledge source to build a RAG QA assistant with clause-level citation traceability, implemented independently on two mainstream low-code platforms (Coze and Dify), with a comparison experiment that quantifies the engineering trade-offs of each architecture.
02 | 工程决策 Engineering Decisions
切分策略 / Chunking Strategy
-
Coze —— Hierarchical(按规范第 X 章 / X.Y 节 / X.Y.Z 条层级切分),保留条款语义完整性
-
Dify —— General + 1024 字符上限(平台默认),作为对照组,验证切分方式对检索质量的影响
-
Coze — Hierarchical chunking (chapter → section → clause: X → X.Y → X.Y.Z), preserving each clause's semantic integrity
-
Dify — General + 1024-character cap (platform default), kept as a control group to test how chunking affects retrieval quality
检索方式 / Retrieval
-
Coze —— Hybrid(语义 + 全文混合检索),Top K = 5,相似度阈值 0.50
-
Dify —— 索引模式经历「经济(关键词)→ 高质量(语义)」切换,Top K = 5,Embedding 模型 text-embedding-3-large(3072 维)
-
Coze — Hybrid retrieval (semantic + full-text), Top K = 5, similarity threshold 0.50
-
Dify — index mode switched from "economical" (keyword) to "high-quality" (semantic); Top K = 5; embedding model text-embedding-3-large (3072-dim)
Anti-Hallucination 三道护栏 / Three Guardrails
-
Prompt 层 —— 强制每条结论附带「GB 55037-2022 第 X.Y.Z 条」格式的条款引用
-
Knowledge Settings 层 —— 配置 No-Recall 时的礼貌拒答 fallback
-
测试层 —— 覆盖正向问答 + 超纲拒答双路径
-
Prompt layer — every answer must carry a citation in the form "GB 55037-2022, Clause X.Y.Z"
-
Knowledge-settings layer — a polite-refusal fallback configured for no-recall cases
-
Test layer — coverage spans both paths: in-scope answering and out-of-scope refusal
03 | 效果验证 Validation
正向测试 / In-Scope Test
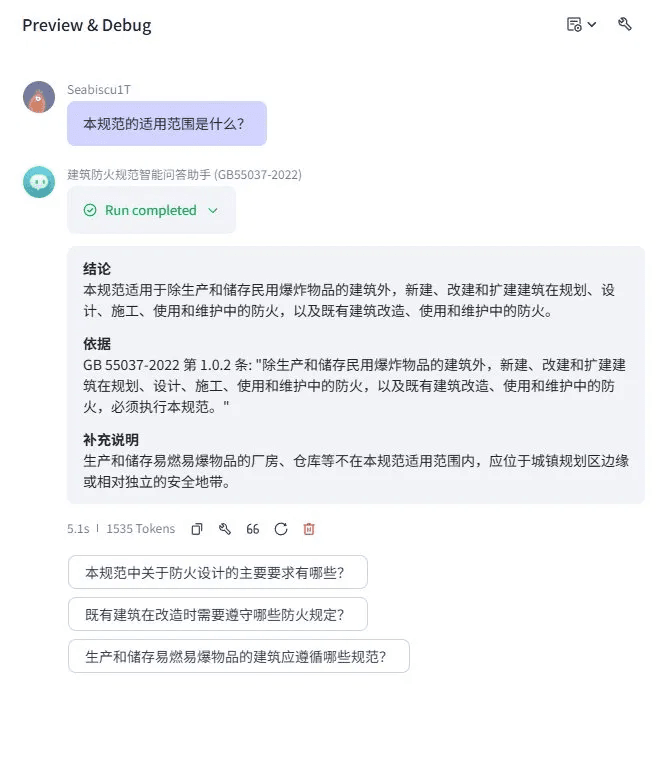
用户提问:「本规范的适用范围是什么?」
Query: "What is the scope of this code?"
-
Coze 版 —— 正确召回第 1.0.2 条原文,5.1s / 1535 tokens
-
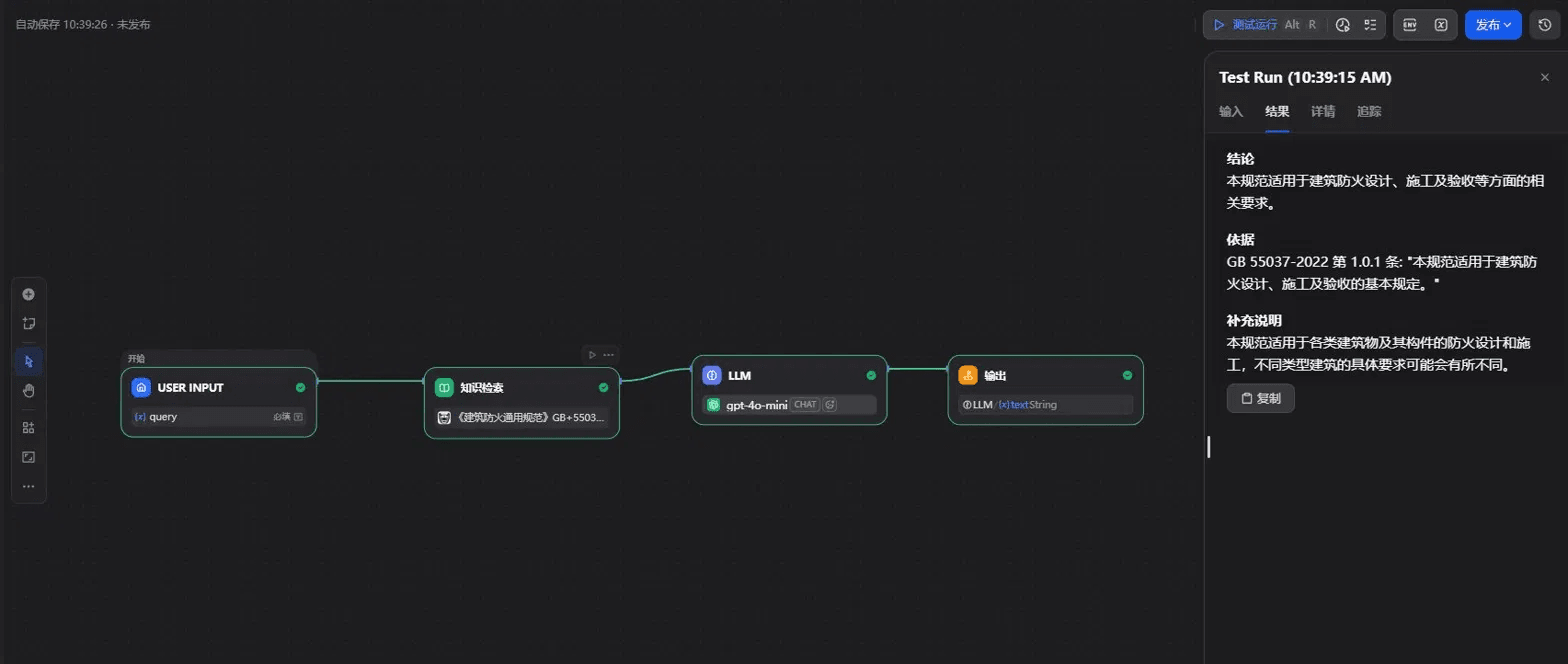
Dify 初版 —— 索引模式为「经济」时,Bot 召回前言混合内容,出现 hallucination
-
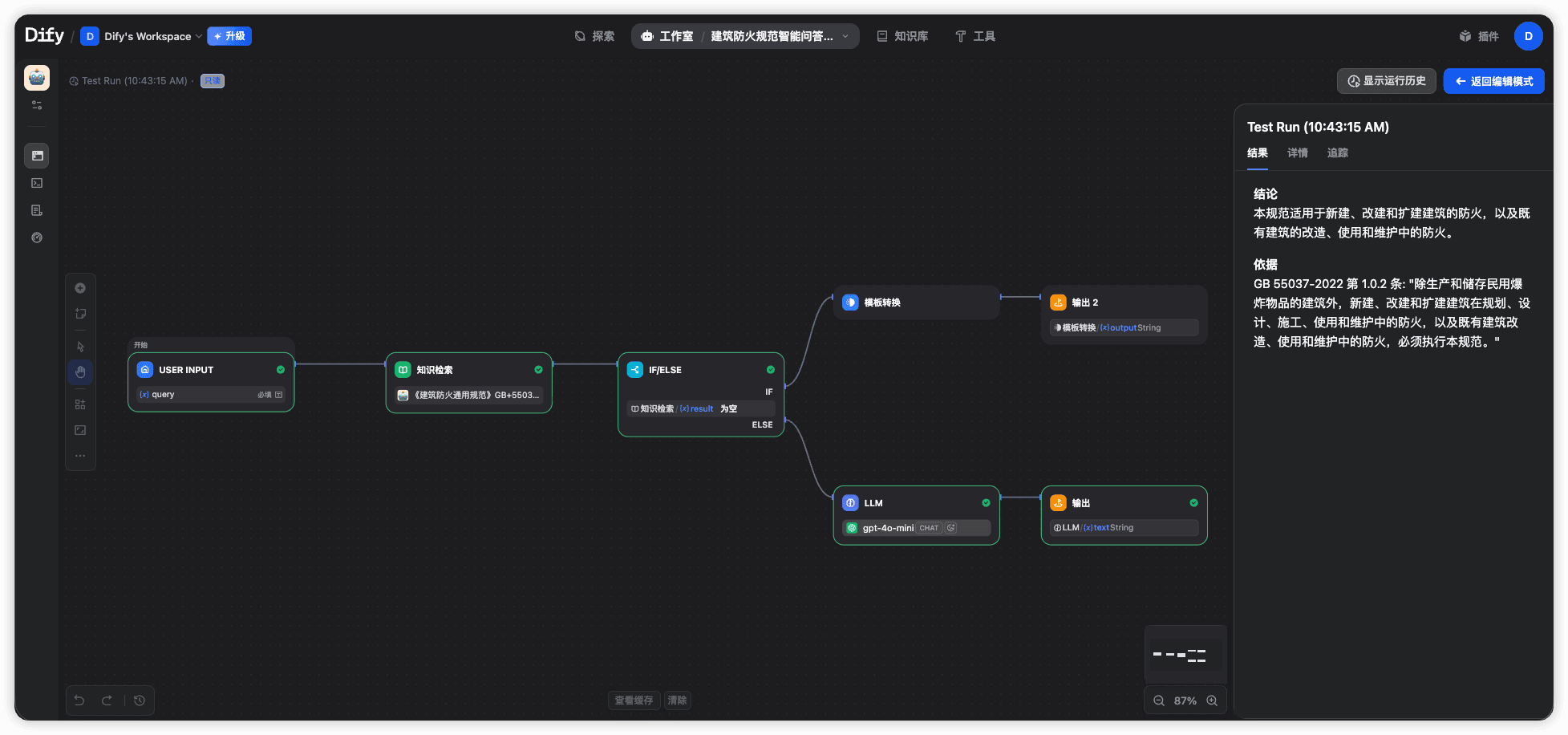
Dify 修正版 —— 切换「高质量」语义索引后,正确召回 1.0.2 条原文(对齐 Coze)
-
Coze — correctly recalled Clause 1.0.2 verbatim — 5.1s / 1535 tokens
-
Dify (initial) — under "economical" indexing, the bot recalled mixed preface content and hallucinated
-
Dify (fixed) — after switching to "high-quality" semantic indexing, it correctly recalled Clause 1.0.2, aligned with Coze
关键工程结论 / Key finding
把 LLM 从 gpt-4o-mini 升级到 gpt-4o 后,Bot 仍然产生错位回答;但仅将索引模式从「经济(关键词倒排)」切到「高质量(向量语义)」,即使保持原 gpt-4o-mini,Bot 也恢复正确召回。在术语—语义错配显著的领域文档(规范 / 法律 / 医学)上,检索质量决定 RAG 系统的上限,模型能力只是下限——投入更强的模型不会修复检索缺陷。
Upgrading the LLM from gpt-4o-mini to gpt-4o did not fix the misaligned answers. But switching the index mode alone — from economical (keyword inverted-index) to high-quality (vector semantic) — restored correct recall even on the original gpt-4o-mini. On domain documents with sharp term-vs-semantics mismatch (codes, law, medicine), retrieval quality sets the ceiling of a RAG system and the model only sets the floor — throwing a stronger model at a retrieval defect won't fix it.
拒答路径 / Out-of-Scope Refusal
用户提问:「民用建筑的容积率上限是多少?」两版 Bot 均礼貌识别为超纲问题,引导用户查询对应专项规范,未编造条款号。
Query: "What is the maximum plot ratio for civil buildings?" Both bots politely identified this as out of scope, pointed the user to the relevant specialized code, and fabricated no clause numbers.
04 | 技术栈 Tech Stack
- Coze + Dify(低代码 RAG 平台 / low-code RAG platforms)
- text-embedding-3-large(向量嵌入,3072 维 / vector embeddings, 3072-dim)
- GPT-4o / GPT-4o-mini(LLM 生成 / generation)
- Hierarchical / General Chunking
- 向量检索 + 关键词倒排索引对照实验 / vector retrieval vs. keyword inverted-index (controlled comparison)
05 | LangChain 自研实现 Building It From Scratch
Coze 和 Dify 让我理解了 RAG 的「产品形态」,但每一步底层都是平台替我做的——切块、嵌入、检索、Prompt 编排,我只是配置参数,真正的工程决策权在平台。LangChain 版本是完全代码实现,目的是把「每个组件做什么、为什么这样做」在自己手里走一遍。
Coze and Dify taught me the "product shape" of RAG, but the platform made every underlying decision for me — chunking, embeddings, retrieval, prompt orchestration — I was only setting parameters; the real engineering control sat with the platform. The LangChain version is written entirely in code, to walk through "what each component does and why" with my own hands.
| 平台 Platform | 实现方式 How | 工程控制权 Control |
|---|---|---|
| Coze | 拖拽 + 配置 / drag-and-drop + config | 低 / Low |
| Dify | 可视化 workflow / visual workflow | 中 / Medium |
| LangChain | 每一行代码自己写 / hand-written code | 完全 / Full |
第三个版本:用 LangChain (LCEL) 从零写出完整 RAG 管线,把平台替我做的每个决策收回自己手里。
验证我不只是『会配置 RAG 平台』,而是理解 RAG 每个组件的工程取舍、能自己写出来。
- 从『会用 AI 工具』上升到『会写 AI 应用代码』
- 完整掌握 LangChain LCEL、向量库、嵌入模型、prompt engineering 的工程组合
- 再次验证:RAG 的真实瓶颈在检索质量与切块策略,不在 LLM 推理能力
↓ READ FULL CASE↑ COLLAPSE
GitHub 仓库 / Repository
s1mple4869/langchain-rag-firecode ↗
技术栈 / Tech Stack
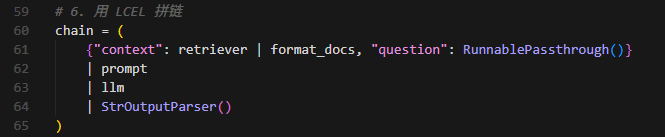
- 框架 / Framework —— LangChain(LCEL)
- LLM —— DeepSeek-V3(via OpenRouter)
- 嵌入模型 / Embeddings —— BAAI/bge-small-zh-v1.5(本地运行、中文专精、CPU 友好 / local, Chinese-specialized, CPU-friendly)
- 向量库 / Vector store —— Chroma(本地持久化 / local persistence)
- PDF 解析 / PDF parsing —— pypdf
关键工程决策 / Key Engineering Decisions
-
嵌入模型选 BGE 本地版而非 OpenAI —— 中国大陆访问 OpenAI 嵌入 API 不稳定,BGE 本地零依赖,且中文场景质量更优。
-
LLM 选 DeepSeek-V3 —— 成本极低、国内可直连;RAG 场景对 LLM 推理要求不极致,DeepSeek 完全够用。
-
API key 通过 .env 管理 —— 硬编码进代码是工业界禁忌,.env + .gitignore 是基本素养。
-
Local BGE over OpenAI embeddings — OpenAI's embedding API is unreliable from mainland China; BGE runs locally with zero dependency and performs better on Chinese text.
-
DeepSeek-V3 as the LLM — very low cost and directly reachable domestically; RAG doesn't demand extreme reasoning, so DeepSeek is more than enough.
-
API keys via .env — hardcoding keys is an industry taboo; .env + .gitignore is table stakes.
测试效果 / Test Results
Test 1(正常问题 / In-scope)
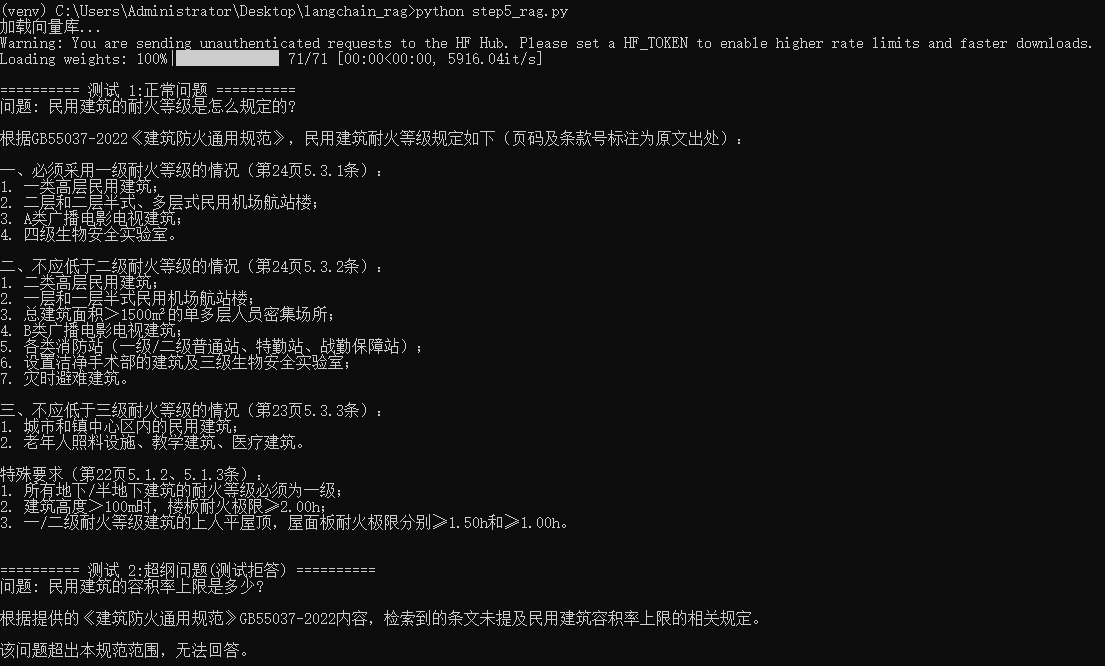
Q:民用建筑的耐火等级是怎么规定的? / How are fire-resistance ratings for civil buildings defined?
A:按耐火等级一 / 二 / 三级分类,引用 5.3.1 / 5.3.2 / 5.3.3 条款 + 5.1.2 / 5.1.3 特殊要求,每条都标注页码。 / A graded answer across Grade I / II / III, citing Clauses 5.3.1 / 5.3.2 / 5.3.3 plus special requirements 5.1.2 / 5.1.3 — each with page numbers.
Test 2(超纲拒答 / Out-of-scope)
Q:民用建筑的容积率上限是多少? / What is the maximum plot ratio for civil buildings?
A:「检索到的条文未提及民用建筑容积率上限的相关规定。该问题超出本规范范围,无法回答。」 / "The retrieved clauses do not mention any limit on plot ratio for civil buildings. This question is outside the scope of this code and cannot be answered."
对比 Dify 早期版本(gpt-4o-mini + 经济索引)曾幻觉编造 1.0.1 条款——LangChain 版本完全消除幻觉,再次印证检索质量是 RAG 可靠性的根本,而非 LLM 推理能力。
Where the early Dify build (gpt-4o-mini + economical index) once hallucinated a fabricated Clause 1.0.1, the LangChain build eliminated hallucination entirely — reaffirming that retrieval quality, not LLM reasoning, is the foundation of RAG reliability.
这一版的收获 / Takeaways
- 从「会用 AI 工具」上升到「会写 AI 应用代码」 / From "using AI tools" to "writing AI application code"
- 完整掌握 LCEL、向量数据库、嵌入模型、prompt engineering 的工程组合 / A full working grasp of LCEL, vector databases, embedding models, and prompt engineering as one stack
- 理解 RAG 真实瓶颈不在 LLM,而在检索质量与切块策略 / Understanding that the real RAG bottleneck is retrieval quality and chunking, not the LLM